GPGPU : neural networks on a graphic card
I had an idea last week while browsing through the shading languages-related websites : as it is now possible to ask to graphic card to perform custom operations on vertices and pixels, why not try to hack all this massive parallel computing power and make it do neural network computing ?</p>
The idea of performing general purpose computations on graphic cards’ GPUs (Graphical Processing Unit) actually seems to be in the air right now (also in this article), with lots of labs working on many different applications to this technique (for instance, see AT&T’s labs dedicated page).</p>
There are two technologies of shading languages : HLSL (High Level Shading Language) for DirectX, and GLSL (OpenGL Shading Language), which are obviously incompatible. I currently only have a Mac so I shoudn’t bother about DirectX, but I wouldn’t want to be prevented from porting my code someday…</p>
So I chose to use Cg (C for Graphics), which is a library from nVidia that defines a new, higher level, shading language, that can be dynamically compiled to HLSL, GLSL or assembly code. It has several profiles, each of which representing a set of capabilities of the underlying hardware, and it’s very simple to use.</p>
My main goal, right now, is to implement a multi-layer perceptron. I had already written a comprehensive neural networks API in Java, with graphical feedback, oriented towards image classification. I found it pretty fast (I produced the fastest Java code I was able to :-D), but with neural network things are never fast enough (especially for training). Hence the idea of writing a neural network API that leverages the GPU power (as well as a CPU-based alternative, as a fallback, in case no programmable GPU is accessible). Indeed, modern GPUs feature parallel processing units that do shading and space-transformations computations for all the geometric elements of a scene and pixels of the screen.</p>
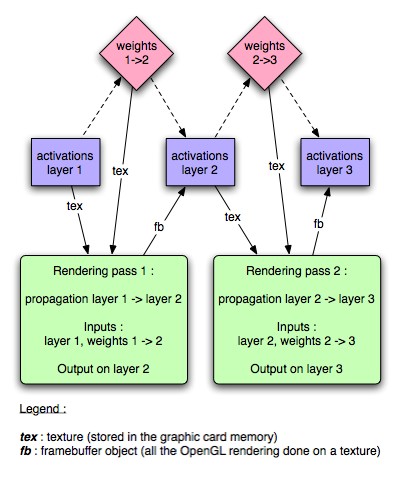
Each layer will be stored in a texture. The computation will be done inside a fragment program, as there seems to be a lot more processing power there than in the vertex processing stage. The input for each fragment program will be the activations from the preceding layer (in a texture) and the weights from the preceding layer to the current layer (in another texture). The output is done in the texture representing the activations of the current layer thanks to a framebuffer object bound to that texture (see the EXT_framebuffer_object OpenGL extension).</p>
As the compilation of the fragment program implies that all loops have to be unrolled, there will be one fragment program for each layer (layers have different sizes in general).
The computing of a network output, given an in put in a texture, will occur as follows :
For each layer (other than the input layer) :</p>
- bind the framebuffer corresponding to this layer’s activation texture
- bind the program corresponding to the links from the previous layer to the current layer
- draw points (each point representing a neuron on the current layer). This is static vertex data that can be stored in a vertex buffer object.
- unbind the program
- unbind the framebuffer
More to come soon… for now I’m gonna enjoy the sun 😀</p>